Líkindafrćđi (Probabilty ) + Ályktunarfrćđi (Inference)
Líkanasmíđi (modelling): Einfölduđ mynd af raunveruleika
Ályktun = líkan + gögn
Upprifjun Líkindafrćđi, nokkur hugtök
Tilraun, atburđur, líkur
Reiknireglur um líkur, óháđir atburđi, skilyrtar líkur, Regla Bayes
Random breyta = Hending (e. Random variable)
Eiginleikar hendinga, samfelldar/sundurslitnar
Dreifing: Dreififall(cdf) , ţéttifall (density, pfd), líkandafall (pmf=probability mass function)
Lýsitölur fyrir dreifingar, vćntanleg gildi (expected value), dreifni (variance), miđgildi (median ) o.s.frv.
Margvíđar hendingar, samand hendinga, fylgni.
Reiknireglur fyrir vćntanlegt gildi og varíans(dreifni)
Ýmsar dreifingar, hvers vegna hafa ţćr nafn, verkefni.
Ályktunarfrćđi, Mat (punktmat, bilmat) Kenningaprófanir
Mat, Punktmat, Metill(estimator), hlutdrćgni(bias),
samkvćmni ( consistency), nýtni (efficiency)
Mat, Bilmat, öryggismörk (confidence limits).
Kenningaprófanir, Núllkenning, valkostur, villa I, villa II, marktćkni(significance), styrkur (power) Verkefni
Tveir skólar ályktunarfrćđi, Hefđbundinn(tíđni-skóli),
Bayesian skóli.
Ađhvarf(regression) og fylgni(correlation)
Ýmsar tegundir af breytum.
Ađhvarf međs einni skýristćrđ,
ađhvarf međ mörgum skýristćrđum,
tengsl viđ ANOVA,
tengsl viđ samanburđ međaltala Verkefni
Tegundir parametra (í. stika), main effects, interactions, intercept, slope. Túlkanir.
Nokkur atriđi um matsađferđir.
GLIM fjölskyldan
Venjuleg ANOVA, ađhvarfslíkön,
Tilraun (experiment), ađgerđ sem gefur útkomu
Ůtkoma óviss, atburđur = mengi af útkomum
Mengja-stćrđfrćđi hentug,
A ![]() = atburđurinn A og B
= atburđurinn A og B
A ![]() B = atburđurinn A eđa B (geta veriđ báđir)
B = atburđurinn A eđa B (geta veriđ báđir)
![]() = mengi af öllum mögulegum útkomum
= mengi af öllum mögulegum útkomum
Líkur
P vörpun sem úthlutar atburđi tölu á milli 0 og 1.
P(A ![]() B) = P(A) + P(B) - P(A
B) = P(A) + P(B) - P(A ![]() B)
B)
Óháđir (independent) atburđir
P(A ![]() B) = P(A) P(B)
B) = P(A) P(B)
skilyrtar líkur (conditional probability)
A ![]() B = atburđurinn A gefiđ atburđurinn B
B = atburđurinn A gefiđ atburđurinn B
P(A ![]() B) = P(A
B) = P(A ![]() B)/P(B)
B)/P(B)
regla Bayes
P(A ![]() B) = P(B
B) = P(B ![]() A) P(A)/P(B)
A) P(A)/P(B)
Dćmi: Á ađ mótefnamćla population?
Segjum 250.000 manna population,
prevalence = 500
sensitivity = specificty =0.95
reikniđ P(S=+ ![]() T=+)
T=+)
svar: P(S=+ ![]() T=+)*250.000
T=+)*250.000
= mörg ţúsund
Dreififall(Cdf) hendingar
F(x) = P(X ![]() x) (ath. stórt og lítiđ x)
x) (ath. stórt og lítiđ x)
ţéttifall(density, pdf) líkindamassafall (pmf)
f(x) = F![]() (x) ef X er samfelld
(x) ef X er samfelld
f(x) = P(X=x) ef X er sundurslitin
Lýsitölur fyrir hendingar
E(X) = expected value =vćntanlegt gildi
E(X) = ![]() x f(x) dx ef X er samfelld
x f(x) dx ef X er samfelld
E(X) = ![]() x f(x) ef X er sundurslitin
x f(x) ef X er sundurslitin
V(X) = variance X = dreifni X
V(X) = ![]()
![]() = E(X-E(X))
= E(X-E(X))![]()
![]() = stađalfrávik X
= stađalfrávik X
x![]() = q-kvantíll
= q-kvantíll ![]() F(x
F(x![]() )=q
)=q
Margvíđar hendingar (multivariate random variables)
F(x,y) = P(X ![]() x
x ![]() Y
Y![]() y)
y)
f(x,y) = F-diffrađ fyrir samfelldar hendingar
f(x,y) = P(X=x ![]() Y=y) fyrir sundurslitnar
Y=y) fyrir sundurslitnar
X og Y óháđar ![]() F(x,y)=F(x)F(y)
F(x,y)=F(x)F(y)
Y![]() X hefur dreififall F
X hefur dreififall F![]() (y
(y![]() x)
x)
Reiknireglur vćntanlegt gildi og varíans
E(aX) = a E(X)
V(aX) = a![]() V(X)
V(X)
Fylkja-algebra (matrix-algebra mjög ţćgileg
Ef X er vektor af hendingum
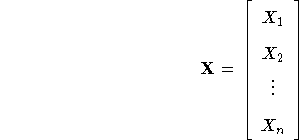
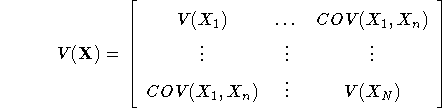
![]()
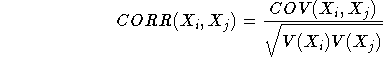
Nokkrar tegundur sundurslitinna (discrete) dreifinga
Bernoulli (p)
Binomial, B(n,p)
Poisson, ![]()
Geometric (p)
Negatív binomial (r,p)
Uniform (a,b)
Nokkrar tegundir samfelldra hendinga
Uniform (a,b)
Exponential ![]()
Gamma (r, ![]() )
)
Normal N( ![]() ,
, ![]() )
)
![]() (k)
(k)
t(k) cauchy=t(1)
F(n,m)
Verkefni
Búiđ til 30 mćlingar úr a) exponential dreifingu međ međaltal
180, b) N(180,7![]() ) og c) cauchy međ miđgildi 180, og 5% meira en 190.
Reikniđ úrtaksmeđaltal, úrtaksstađalfrávik og stađalfrávik úrtaksmeđaltalsins.
Endurtakiđ fyrir úrtaksstćrđ 300 og 3000.
) og c) cauchy međ miđgildi 180, og 5% meira en 190.
Reikniđ úrtaksmeđaltal, úrtaksstađalfrávik og stađalfrávik úrtaksmeđaltalsins.
Endurtakiđ fyrir úrtaksstćrđ 300 og 3000.
Verkefni Búiđ til 30 mćlingar úr normaldreifingu međ međaltal 0 og stađalfrávik 1. Reikniđ 95Endurtakiđ 50-1000 sinnum. Notiđ tölvu og viđeigandi forrit. T.d. EXCEL eđa einhvern annan töflureikni.
Verkefni
Búiđ til 30 mćlingar úr normaldreifingu međ međaltal 0 og
stađalfrávik 1. Prófiđ kenninguna ađ međaltaliđ sé 0 og gangiđ út
frá ađ vitađ sé ađ stađalfrávik sé 1. Er kenningunni hafnađ miđađ
viđ ![]() =0.05? Enrdurtakiđ 50-1000 sinnum.
=0.05? Enrdurtakiđ 50-1000 sinnum.
Verkefni
Búiđ til 30 mćlingar úr normaldreifingu međ međaltal 0.2 og
stađalfrávik 1. Prófiđ kenninguna ađ međaltaliđ sé 0 og gangiđ út
frá ađ vitađ sé ađ stađalfrávik sé 1. Er kenningunni hafnađ miđađ
viđ ![]() =0.05? Enrdurtakiđ 50-1000 sinnum.
=0.05? Enrdurtakiđ 50-1000 sinnum.
Verkefni
Búiđ til 30 mćlingar úr normaldreifingu međ međaltal 0.4 og
stađalfrávik 1. Prófiđ kenninguna ađ međaltaliđ sé 0 og gangiđ út
frá ađ vitađ sé ađ stađalfrávik sé 1. Er kenningunni hafnađ miđađ
viđ ![]() =0.05? Enrdurtakiđ 50-1000 sinnum.
=0.05? Enrdurtakiđ 50-1000 sinnum.
Nokkur atriđi um logistic regression
Ţađ sem meta á eru líkur á ákveđnum atburđi, t.d. bilun sjúkdómi eđa ţess háttar. Köllum ţá breytu Y. p=P(Y=1), 1-p=P(Y=0). Gerum ráđ fyrir ađ
p= e![]() / (1 + e
/ (1 + e![]() )
)
sem er jafngilt og
log(p/(1-p)) = ![]()
Likelihood-fall fyrir eina mćlingu er:
L(![]() | y,x) = p
| y,x) = p![]() (1-p)
(1-p)![]()
log(L) = y log(p) + (1-y) log (1 - p)
Fyrir n óháđar mćlingar er log-likelihood falliđ ţví
![]() ( y
( y![]() log(p
log(p![]() ) + (1-y
) + (1-y![]() ) log (1-p
) log (1-p![]() ))
))
p![]() = e
= e![]() / (1 + e
/ (1 + e![]() )
)
Nokkur atriđi um survival-greiningu.
Helstu hugtök S(t) survival fall, S(t) = 1 - F(t) ţar sem hendining T er endingartími ţess sem rannsaka skal.
h(t) hazard fall, h(t) = f(t)/S(t)
H(t) cumulative hazard fall, H(t) = ![]() h(s) ds
h(s) ds
Dćmi, Líftími exponential dreifđur, f(t) = ![]() e
e![]()
ţá er S(t) = 1 - F(t) = 1 - (1 - e![]() ) = e
) = e![]()
og
h(t) = f(t)/S(t) = ![]() e
e![]() /e
/e![]() =
=
![]()
H(t) = ![]() t
t
Censoring, ţađ liggur í hlutarins eđli ađ viđ getum ekki séđ heildar feril hvers og eins. Ţađ munu verđa margir sem viđ vitum ekki dánardćgur á. Til eru ýmsar tegundir af censoring.
Ađferđir til ađ meta survival feril. E.t.v. best ţekkt Kaplan-Meier og Flemming-Harrington. Einni hugsanlegt ađ negla niđur fyrirfram ákveđiđ form eins og t.d. Weibull-dreifingu.
Oft er S(t) sjálft ekki ađaláhugamáliđ heldur samanburđur ýmissa hópa og áhrif skýristćrđa.
Get gefiđ mér fjölskyldu af líftímadreifingum, weibull, log-normal, log-logistic o.s.frv. og síđan framkvćmd einhvers konar ađhvarfsgreiningu. (eins konar GLM)
Cox-regression, gengur út á ađ hćgt sé ađ ţátta hazardfalliđ h(t)á á eftirfarandi hátt
h(t,x) = hazard fall fyrir einstakling međ eiginleika x
= h(t) exp(x![]() )
)
Ţ.e. ađ ein grunn-hazard lína gildi fyrir alla og síđan sé munurinn
eingöngu fólginn í ţćttinum exp(x![]() ).
).
Nokkur atriđi um tölfrćđilega líkanagerđ
Skilgreina markmiđ
Skilgreina áhugaverđ tengsl, átta sig á truflandi ţáttum
Viđ experimental ađstćđur, kynna sér experimental design til ađ fá hámarksupplýsingar út úr mćlingunum.
Setja fram hugsanlegt líkan, ţ.e. átta sig á hugsanlegri dreifingu mćlinga, hugsanlegu formi líkans.
Meta Líkan, t.d. međ maximum-likelihood ađferđ.
Framkvćma ítarlega diagnostics, leifaskođun (residual analysis). Ŕtta sig á ađ hvernig líkan misstígur sig. Átta sig á outliers og influential observations. Athugiđ ađ til eru margs konar leifar, í venjulegum normal líkönum, t.d. least-squares residuals og recursive residuals. Ě GLIM og survival eru margskonar leifar.
Ef líkan stendst skođun túlka niđurstöđur. Varist over-fitting, ţ.e. ađ finna líkan sem hentar mćldum gögnum afar vel en gćti misstígiđ sig illa ef ţví vćri beitt á annađ gagnasett. Almennt gildir ađ velja skuli líkönin sem minnst (principle of parsimony)